


One of our aims with our global illumination implementation was to keep it as simple as possible, while still obtaining good performance, and we hoped to achieve that by using the GPU. While the are several approaches to compute global illumination in the GPU, the most simple one that we could come up with was to use our existing rendering engine to estimate global illumination using a fixed sequence of final gathering steps. That is, rendering the scene from every lightmap texel to gather all the incoming irradiance at that point, integrating it to compute the output radiance, and repeating these steps multiple times until the lightmaps converge to an approximate solution. This is basically the same procedure described by Hugo Elias.

Using the same engine makes it very easy to keep the global illumination in sync with the rest of the game. If we add new shaders or materials, change the representation of the geometry or alter the world, keeping the global illumination up to date requires little o no effort. Another interesting benefit is that optimizations to the rendering engine also benefit the global illumination pre-computation. However, as we will see later, in practice each application stresses the system in different ways and end up limited by different bottlenecks, what improves the rendering time does not necessary improve the pre-computation and vice-versa.
Projection Methods
I tried several different approaches to render the scene and estimate the incoming radiance. The most common approach is to render hemicubes; that requires rendering the scene to 5 different viewports. Several sources suggested the use of spherical or parabolic projections, but in my experience these approaches produced terrible results due to the non linear projection. Without very high tessellation rates the scene would become unacceptably distorted, creating gaps between objects or making parallel surfaces self-intersect.

In GPU Gems 2, Coombe et al. suggested to project the z value independently of (x,y) coordinates using an orthographic projection in order to maintain a correct depth ordering. As seen in the next picture, that removed the most obvious artifacts; note how the staircase inside the tower is not visible anymore:

However, while this works OK from some points of view, the distortion becomes unacceptable when the camera is close to a surface, which is always our case. So, in practice these approaches are not very useful. Note how the outdoors are visible when sampling the lighting from the interior of the tower:

Other implementations use a single plane projection. This kind of projection does not capture the whole hemisphere, but by using a wide field of view it's possible to capture about 80% of it. I haven't actually tried this approach, but to get an idea of what the results would look like, I modified the hemicube integrator to ignore 20% of the samples near the horizon and found out that this introduced artifacts that were unacceptable for high-quality results.
Pascal Gautron estimates that on typical scenes this approach introduced a 18% RMS error, but suggests various tricks to reduce it by re-balancing the solid angle weights, or extrapolating the border samples and filling the holes. The latter method reduces the error down to a mere 6%.
However, these improvements do not eliminate banding artifacts caused when an intense light source visible from one location is suddenly not visible anymore in the next when it falls out of the projection frustum. To make things worse, the projection lacks rotational invariance, which enhances the problem when hemicubes are rendered with random rotations. So, while in many cases the results look alright, the few cases that do not render the method impractical.
Another problem is that the wide frustum is 4 times larger than the equivalent hemicube and easily intersects with the surrounding geometry; as I'll discuss next, this is one of the main problems that I had to deal with.
In the end I simply stayed with the traditional hemicubes for simplicity. I think it would have been possible to do somewhat better using a fancy tetrahedral or pyramidal projection with 3 or 4 planes, but that didn't seem worth the trouble.
Hemicube Overlaps
As I just mentioned, one of the main problems that I had to solve was to handle overlaps between the hemicubes and the geometry. These overlaps are unavoidable unless you impose some severe modeling restrictions that are not desirable for production.
When the geometry is well formed and does not have self-intersections, these overlaps can sometimes be avoided with centroid sampling. Without centroid sampling the location where the hemicube is rendered from can easily end up being outside of the polygon that contains the sample and thus inside another volume.

With centroid sampling the origin of the hemicube is now always inside the surface. However, it can still be very close to the surface boundary and have overlaps with nearby surfaces. A simple solution is to move the near plane closer to the camera until the overlap dissapears, but how close? The distance to the nearest boundary can be determined analytically, but there's a limit in how much the near plane distance can be reduced without introducing depth sampling artifacts. An interesting solution for this problem is to render multiple hemicubes at the same location, each hemicube enclosing the previous one with its far plane at the near plane of the next.
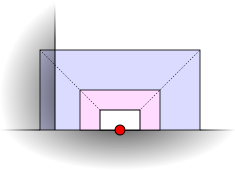
That would solve most the problems when the geometry is watertight and centroid sampling is used, but in many cases our assets are not always well conditioned. So, I had to find a more general solution.
I tried all sort of heuristics, to render backfaces in black, to fill them with the average color, to extrapolate the nearest colors, etc. None of these solutions worked well in all cases. In the end, something that produced satisfactory results was to render the backfaces with a special tag to distinguish them from front facing faces when integrating the hemicubes. Whenever a hemicube had too many tagged texels it would be discarded entirely, and instead its output radiance would be estimated at that location interpolating or extrapolating it from the nearest valid samples.
The extrapolation is not always correct, and the detection of invalid hemicubes is not 100% accurate, but so far this is the method that I'm happiest with. In the next article I'll explain how this extrapolation is done in more detail.
Shadow Rendering
While the goal was to use the same rendering engine, using its shadow system 'as is' would have been overkill. We are using cascade shadow maps, which are updated on every frame, and to maximize the shadow map resolution the shadow maps are tightly aligned to the view frustum slices. When rendering the hemicubes, shadow map resolution is not that important, and re-rendering the shadows for each hemicube face is unnecessarily expensive. To keep things simple I still used cascade shadow maps, but instead of rendering them for each view, I only rendered them once for each object positioning the cascades around the center of the object.
Rasterization
Now that I've explained how to capture the irradiance of the scene at any point, it's necessary to sample it for every lightmap texel. To do that I simply rasterize the geometry in the lightmap UV space using a conservative rasterizer and render one hemicube at every fragment whose coverage is above certain threshold.
One nice thing of using our own rasterizer is that I can evaluate the exact coverage analytically. Since the parameterization does not have overlaps, the coverage is just the area of the intersection of the texel square with the polygon being rasterized. Similarly, the centroid is the center of mass of the clipped polygon.
This approach gives us a position and a direction to render the hemicube from, but I still need to determine the orientation of the hemicube. Initially, I simply chose an arbitrary orientation using the traditional/standard method, but that resulted in banding artifacts:

The source of the problem is just the limited hemicube resolution, but it's surprisingly hard to get rid of it entirely by only increasing the hemicube size. A better solution is to simply use random orientations:

Note that I am trading banding artifacts by noise, but the latter is much easier to get rid of by using some smoothing.
Integration
Once the hemicubes have been rendered it's necessary to integrate the sampled irradiance to compute the output radiance. The integral of the irradiance hemicube is simply a weighted sum of the samples, where the weights are the cosine-weighted areas of the hemicube texels projected on the hemisphere, that is, the cosine-weighted solid angles of the texels. These weights are constant, so they can be precomputed in advance.
In the article by Hugo Helias that I referenced in the introduction the same approach is used and this weight table is called the "The Multiplier Map". Beware of that part of the article, though, because there's a bug in the formulas. The subtended solid angle of the texel is not "the cosine of the angle between the direction the camera is facing in, and the line from the camera to the pixel":
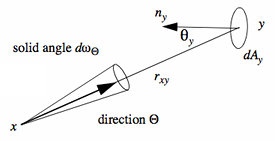
![]()
That term needs to be divided by the squared distance between the location of the camera x and the center of the texel y:
![]()
See formula 25 in the Global Illumination Compendium for more details.
Also, since this is a precomputation it made sense to evaluate the solid angle exactly. That can be derived using Girard's formula or directly using the handy formula in Manne Ohrstrom's thesis. Doing so improved the invariance of the integral with respect to rotations of the hemicube and that reduced noise significantly.
In the end, the integration is a fairly simple operation. It could be done very efficiently using compute shaders and I might still do that in the future, but for prototyping purposes it was much easier to perform the integration in the CPU. Unfortunately, that required transferring the data across the bus and, if not done properly, it severely reduced performance.
Asynchronous Memory Transfers
Contrary to popular belief, Direct3D 9 provides a mechanism to perform memory copies asynchronously. In Direct3D 10 and OpenGL this is done through staging resources or pixel buffer objects; in Direct3D 9 something similar can be achieved with offscreen plain surfaces. The problem is that this is not very well documented, it's very easy to fall out of the fast path, and the conditions in which that happens are slightly different for each IHV.
In the first place, you have to create two render targets and offscreen plain surfaces:
dev->CreateRenderTarget(..., &render_target_0); dev->CreateRenderTarget(..., &render_target_1); dev->CreateOffscreenPlainSurface(..., &offscreen_surface_0); dev->CreateOffscreenPlainSurface(..., &offscreen_surface_1); |
If you have more than two targets the copies become synchronous in some systems, but two is sufficient to generate enough work to do in parallel with the memory transfers.
The most important observation is that the only device method that appears to be asynchronous is GetRenderTargetData. After calling this method, any other device method blocks until the copy is complete. So, instead of overlapping the memory transfer with the rendering code, you have to find some CPU work to do simultaneously. In my case, I just do the integration of one of the render targets while copying the other:
while hemicubes left { [...] // Render hemicube to render_target_0 // Initiate asynchronous copy to system memory. dev->GetRenderTargetData(render_target_0, offscreen_surface_0); // Lock offscreen_surface_1 // at this point the corresponding async copy has finished already. offscreen_surface_1->LockRect(..., D3DLOCK_READONLY); [...] // Integrate hemicube. offscreen_surface_1->UnlockRect(); swap(render_target_0, render_target_1); swap(offscreen_surface_0, offscreen_surface_1); } |
Another problem is that the buffer needs to be sufficiently big to reach transfer rates that saturate the available bandwidth. In order to achieve that I batch multiple hemicubes in a single texture atlas as seen in the following picture:

In practice I do not render the hemicubes using the depicted cross layout, but instead arrange the faces tightly in a 3x1 rectangle that does not waste any texture space and maximizes bandwidth. However, the cross layout was useful to visualize the output for debugging purposes.
Performance and Conclusions
The performance of our global illumination solution is somewhat disappointing. While we do most of the work on the GPU we are not really making a very effective use of it. The main GPU bottleneck is in the fixed function geometry pipeline; we are basically rendering a large number of tiny triangles on a small render target.
But that's not the main problem. Traversing the scene in the CPU and submitting commands to render it actually takes more time than it takes the GPU to process the commands and render the scene, so the GPU is actually underutilized.
Our engine was designed for quick prototyping, to make it very easy to draw stuff with different materials, but not to do so in the most efficient way possible. These inefficiencies became a lot more pronounced in the lightmap baker.
On the bright side, as we optimize the CPU side of the engine we expect performance to improve. Modern GPUs also have functionality that make it possible to render to multiple hemicube faces at once. We expect that will also reduce the CPU work significantly.
While it was easy to get our global illumination solution up and running by reusing our rendering engine, bringing it to a level of sufficient quality and performance took a considerable amount of time. In the next installment I'll describe some of the techniques and optimizations that I implemented to fix some of the remaining artifacts and improve performance.
Great post clearly explained. It’s really interesting to see the implementation evolve from prototype to production.
Awesome post! That must have taken a long time to put together with all the nice diagrams and debug visualizations.
I’m a little bit ‘grossed out’ by the choice to use hemicubes on the GPU due to the inflexibility and CPU scene traversal bottlenecks instead of ray tracing which is trivially parallelizable and much more flexible (importance sampling), but it’s really useful to see all the stuff that’s involved with that approach. The async transfer in DX9 is especially interesting, no doubt I’ll find a use for that somewhere.
Since you are reading the data back to the CPU, is there a reason you can’t use irradiance caching to reduce the number of final gathers and speed up the process? Irradiance caching is also really useful for smoothing the results too because you can just interpolate in a second pass with larger thresholds than you used in the first pass when deciding where to place samples.
@Daniel: Irradiance Caching is the topic of the next post. The main reason why I implemented the integration on the CPU was that the computation of the irradiance gradients was complex enough to make it worth prototyping it on the CPU.
I thought about using NVIRT, since I’m somewhat familiar with it, but there are some disadvantages:
– Having to write and maintain surface shaders for all our materials.
– Dealing with texture limitations in NVIRT. We currently use a lot more textures than NVIRT supports.
– KD-Tree construction times used to be pretty slow, but maybe that has changed recently. The tracer would not be suitable for quick prototyping if you have to rebuild the hierarchy and wait a long time every time you move an object, and it might be too slow if every independent object uses a separate acceleration structure.
On the other side, it would also have other advantages… I would love to hear people’s experiences in this regard.
Great post Ignacio, that was a really good read. Looking forward to part two.
That is just an awesome post, thanks!
Probably a stupid question, since I don’t know anything about the matter: Why is the integration being done on the CPU? Couldn’t you use a GPU shader to integrate from the hemicube texture to an even smaller output texture and only copy that to the CPU?
I really wish that Hugo Elias had kept maintaining his site with ever-more-modern graphics algorithms. It used to be one of my favorite sites, but the only thing on it that’s really applicable anymore is the radiosity article.
I’m glad you liked my site. Sadly I can’t update it for 2 reasons: 1) I don’t do much graphics progamming any more. Moved to robotics, and was, for a time, trying to write a CAD package for designing PCBs (www.liquidpcb.org). 2) I don’t have access to my own site any more, so I can’t add articles or fix errors. :(
Awesome article!
Keep ’em coming =)
Ignacio, is this the first time a game does this or is this something normal that games have already and you just don’t want to use a pre built engine but create your own from scratch?
b/c it sounds as if it’s something revolutionary or something that is noth normal in games or that a lot of games don’t have.
sorry, i’m not a technical person so all that was like reading japanese or something… i’m bearly in my first year of computer science in high school so all the 3d space thing is unknown to me.
the pictures look very pretty, that castle like tower looks very cool and fantasy yet real like. do i even make sense? i remember a few years ago in the Braid blog that Jonathan was talking about “iconic landmarks” and he talked about how iconic things in games should be tied to interactivity (since that is what the meadium is supposed to be about, actual gameplay) with places like 2 fort and de-dust that encourtage sertain types of gameplays and then spaces that just look cool, like that “hell?” level in Painkiller.
i remembered this b/c the concept art of that tower and the windmill look super iconic and immediately recognisable. i wander how interactivity will be in those spaces…
good luck finding all the answers and algorithms and doing all the math, really best of wishes. and be sure to report back to tell us how you did it!
hey guis! i found a site that deals with maze’s architecture and algorithms. i thought it would be interesting for followers of the witness and people interested in spaces… like inInception…
you guys provably read it already, but it’s very informative and educational. really interesting..
http://www.astrolog.org/labyrnth/algrithm.htm
have fun making those trees behave and hemicubing stuff!
Ignacio, could you elaborate a bit on the centroid-sampling part? I confess I didn’t understand it at all. “Without centroid sampling the location where the hemicube is rendered from can easily end up being outside of the polygon that contains the sample and thus inside another volume.” I’m confused – which polygon are we talking about? What is “another volume”?
@Nathan Imagine the intersection between the floor and a wall. Along the intersection, some of the floor texels are partially outside of the floor and inside the wall. If the geometry is manifold, there is an edge along the intersection and the floor does not extend below the wall.
Now you want to compute the lighting of these texels near the wall. However, the center of some of these texels lies outside of the floor polygon (behind the wall). The solution that I propose is to clip the texel quad against the floor polygon and instead of using the center of the quad, use the center of the clipped quad. That’s what’s usually known as centroid sampling and it guarantees that the sampling point is outside of the wall.
Note that on the GPU the centroid is computed approximately numerically by taking a fixed number of samples. In this case, since we don’t have overlaps in the parameterization, we can compute the centroid analytically.
@Ignacio Thanks, that cleared it up.
Ever get round to part 2?
Hi,
Can you update the link to the master thesis?
The old one seems broken, but this one seems to work fine:
https://pdfs.semanticscholar.org/1f23/57fc5a6102b745eb37ba1ab03a9c382de1f2.pdf